
Joins can be a sticky business, especially if…
● You haven’t used them much before.
● You are working with data that is new to you.
● You don’t trust your data cleanliness.
After joining two tables you may wonder, “did the data join correctly?” That question usually has two components:
● Did my join drop any data?
● Did my join duplicate any data?
Here’s a quick test you can use to find out.
When you are going to join two tables of data, hit the view data button to the right of the table name to learn how many rows of data are in that table.

The result:
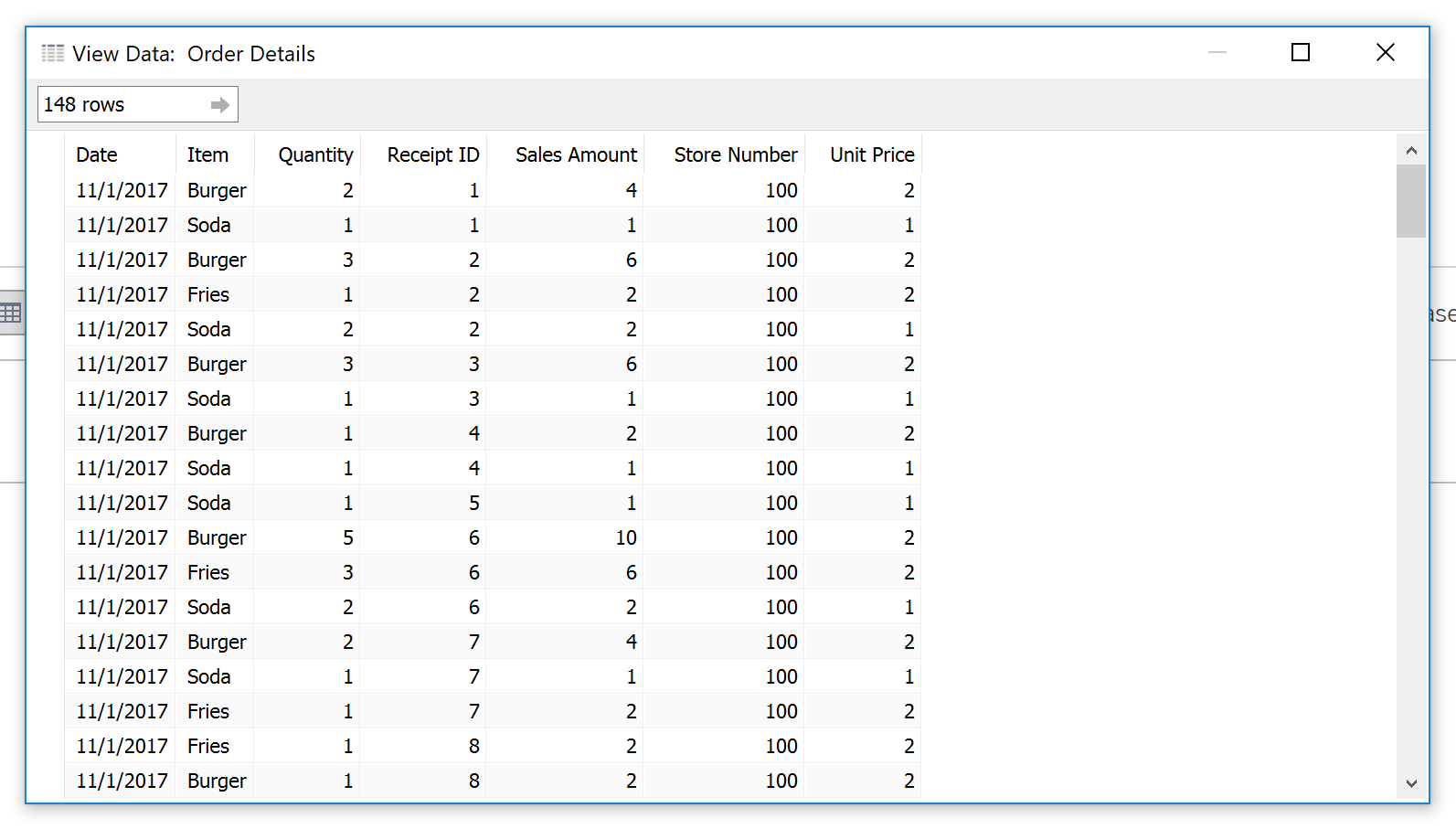
*Hint, if the dialogue shows “10,000 rows” you likely have more data than that. Type in a large number where it says 10,000 rows to learn how many rows there truly are.
Repeat this process for each table you intend to join.

In this case I have two tables, the first has 148 rows of data, the second has 60. As a general rule (there are exceptions) you probably don’t want your output to have more rows than your most detailed table. In this case, I am tying demographic information (city, manager, etc.) to detailed sales data. If everything works correctly, I should have a join result of 148 rows.
Here is the initial result:

Notice the result is 888 rows. Wow! Data is duplicating. This is a rare scenario where Receipt ID isn’t the complete unique identifier to match rows of data from each table. We need to join on multiple fields (Receipt ID, Store Number, and Date) to end up with 148 rows.

What happened previously is that every store has a receipt #100 each day so all the receipt #100s were matching to all the other receipt #100s whether they were a true match or not.
You can also use this approach to find out if your join result has less rows than the initial data tables as well. If that happens, it means that one table didn’t find a join ID match in the other table. That could be due to data cleanliness or the data may purposefully be set up that way.